
「音声認識」そのものは素人には敷居が高いテーマですが,肝心の「認識」の部分については マイクロソフトから音声認識用のSDKが無償で提供されていますので, 「音声認識をしてなにかするソフト」を作ること自体はそう難しいことではありません. 音声認識で動作するソフトが自作できるようになると,声で動くゲームを作ったり, ロボットに声で指令を与えたり,家電を声でコントロールしたりと,いろいろ夢が広がります. 今回はそのSDKのインストールと,サンプルプログラムのいじり方,音声認識エンジンのカスタマイズ の仕方などについて紹介したいと思います. |
説明に入る前に
これを読んで得られるもの
ここに書いてある内容をそのままやれば,
- Windowsで,マイクからの音声入力を使って何かするプログラムが作れるようになる
- 『ドラゴンボール』など任意の単語も認識できるようになる
実験を行った基本ソフトウェア環境
今回のコラム執筆にあたり,実験を行った環境を以下に示します.
- Windows XP
- Visual C++ 6.0
Speech SDKのダウンロードとインストール
Speech SDK は音声認識および音声合成(いわゆる機械の人の声)を行うソフトを作るためのSDKです.
Microsoftの
Speech SDK 5.1
のページから以下の2つのファイルをダウンロードしてください.
- SpeechSDK51.exe(68.0 MB)
- SpeechSDK51LangPack.exe(81.5 MB)
インストールに成功すると,コントロールパネルの中に「音声認識」(もしくは「スピーチ」)という項目が追加されます.
![]() ←こんなの
←こんなの
これを開くとこのようなプロパティが表示されます.
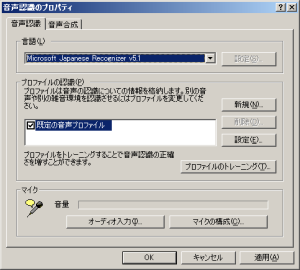
「言語」という項目で「Microsoft Japanese Recognizer v5.1」を選んでOKボタンを押してください.
これで日本語入力(音声→日本語文字出力)となります.
このようにOSから提供される音声認識のAPIは一般にSpeech API (SAPI:サピ)と呼ばれています.
VisualC++6.0の設定
SDKインストール時におなじみの「パスを通す」という作業をします.
これはヘッダファイルとかライブラリファイルの場所をVCに教える作業です.
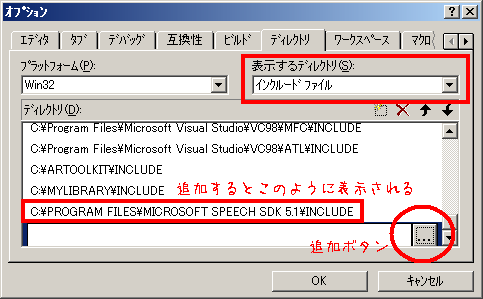
VisualC++6.0を起動して「ツール」>「オプション」>「ディレクトリ」とたどってください.
まず「表示するディレクトリ」を「インクルードファイル」にした状態で,下の空白の横にある「...」ボタンをクリックして
C:¥PROGRAM FILES¥MICROSOFT SPEECH SDK 5.1¥INCLUDE
を追加してください.
次に「表示するディレクトリ」を「ライブラリファイル」にした状態で,同様にして
C:¥PROGRAM FILES¥MICROSOFT SPEECH SDK 5.1¥LIB¥I386
を追加してください.できたらOKボタンを押して終わりです.
とりあえずサンプルプログラムで遊んでみる
さて,インストールが済んだら適当なヘッドセットやマイクなどの音声入力機器を用意して
音声認識というものを体験してみましょう.スタートメニューから次のようにたどってください.
スタート>プログラム>Microsoft Speech SDK 5.1>C++ Samples>Simple Dictation
「Simple Dictation」はC++で書かれた超簡単な音声認識プログラムのサンプルです. そのままマイクに向かって話しかければテキストボックスに文字が表示されます. 『本日は晴天なり』のようなベタな言葉で話しかけてみてください. (マイクに近づき過ぎるとうまく認識できない場合があります.)
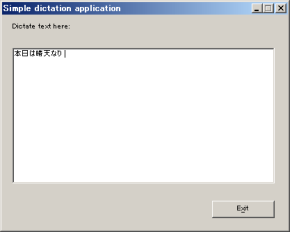
"Dictation"とは書き取りのこと
期待してやってみると,その認識精度の悪さにガッカリするかもしれません. 音声認識エンジンの性能の問題なのですが,デフォルトで入っているエンジンでは マイク・トレーニングを行うことで精度を上げる仕組みになっています. 後ほど,他の音声認識エンジンを利用する方法について述べますので, 精度についてはひとまず置いておき,ソースファイルを眺めてみることにしましょう.
Simple Dictationのソースを解読してみる
Simple Dictationのソースファイル一式は
C:¥Program Files¥Microsoft Speech SDK 5.1¥Samples¥CPP¥SimpleDict
に格納されています.
ソース(SimpleDict.cpp)を見てみると「WinMain」関数のある「Win32 Application」として作られています.
このソースをじっくり読むと以下のようなことがわかります.
- WM_RECOEVENTというユーザメッセージを新たに定義している(simpledict.h)
#define WM_RECOEVENT WM_APP // Window message used for recognition events
- WM_RECOEVENTは音声認識が行われたときに呼ばれるように設定されている
hr = m_cpRecoCtxt->SetNotifyWindowMessage( hDlg, WM_RECOEVENT, 0, 0 );
- WM_RECOEVENTによってRecoEvent()という処理結果を表示する関数が動作する
- RecoEvent()内のdstrTextという変数に認識結果の文字列が格納されている
- COMの初期化と終了処理が必要らしい(CoInitialize()とCoUninitialize())
- InitDialog()の中身がそのまま音声認識に関する初期化らしい
- 音声認識に関する終了処理はこの部分らしい(84行目)
// Release the recognition context and the dictation grammar pThis->m_cpRecoCtxt.Release(); pThis->m_cpDictationGrammar.Release();
以上の要点をおさえて,真似(コピペ)すれば音声認識プログラムの骨子が作れることになります.
dstrTextという変数に認識結果の文字列が格納されているようなので,この文字列に対して 文字検索をかければ所定の単語を含んでいるかどうかをチェックすることができます.
dstrTextという変数はCSpDynamicStringというなんだかよくわからない型になっていますが, サンプルソースにあるようにW2Tマクロで変換が可能なようです.たとえばchar型の変数に 認識結果文字列を格納したければ,以下のようにします.
char text[256]; strcpy(text,W2T(dstrText));
if (strstr(text,"こんにちは")>0) {
AfxMessageBox("こんにちはと言いましたね? 言ったよね!");
}
MFC版 Simple Dictation
VC習い始めからMFC畑で育った私としてはMFCのダイアログベースのほうが何かと都合が良いので
MFCに移植してみました.前項で挙げた箇所をそのままコピペして,適当に修正しています.
![]()
- MFC版SimpleDictationソース一式:VoiceTest(2.37MB)
音声認識エンジンにJulius for SAPIを使おう
Speech SDKにデフォルトで入っている音声認識エンジンは,マイクトレーニングを行うことで 精度を上げる仕組みになっています.しかし,実際にトレーニングをやってみると結構な苦痛です. というわけで他の認識エンジンを利用することにします.
フリーで提供されている国産の音声認識システムにJulius(ユリウス)というものがあります.
大語彙連続音声認識システムJulius
Juliusは「発音辞書や言語モデル・音響モデルなどの音声認識の各モジュールを組み替えることで 様々な幅広い用途に応用できる」というメリットを持っています.つまりいろいろカスタマイズ できるということです.Juliusの配布形態はソース,ライブラリなどさまざまですが, その中にWindowsの音声認識API(SAPI)のエンジンとして利用可能な「Julius for SAPI」があります. 今回はこれを利用します.
Julius for SAPIのダウンロードとインストール
公式サイト:Julius for SAPIダウンロードするもの
- バイナリ(Julius for SAPI インストーラ) Julius_SAPI_2_3.msi
- Julius for SAPI スタンダードモデルインストーラ Julius_SAPI_StandardModels.msi
ダウンロード後,それぞれインストールしてください.
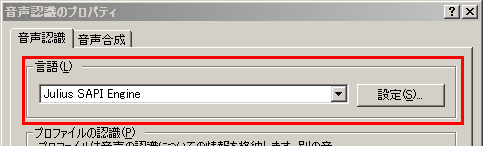
インストールがうまくいくと,コントロールパネルの「音声認識」の設定画面の「言語」のところで
「Julius SAPI Engine」が選択可能になります.
音声認識エンジンを「Julius SAPI Engine」に変更したら,さっそく認識精度を試してみましょう. さきほどと同じようにSimple Dictationなどのプログラムで動作を確認します. …いかがですか? 認識精度の違いに驚かれたかもしれません. Juliusはマイクトレーニングなどを行わずしてかなりの効果を発揮します.
辞書を設定してより賢く
特定の固有名詞(商品名など)を認識させるためには,自分で辞書を作る必要があります. Julius for SAPI ver2.3以降ではclass N-gram形式の辞書ファイルに対応しています. …とエラそうに書きましたが,class N-gramというものの存在を知ったのは今回が初めてで私もよく知りません. 簡単に調べてみたところ,N-gramモデルは情報理論の父クロード・シャノンが考え出した言語モデルで, 「ある文字列の中で,N個の文字列または単語の組み合わせが,どの程度出現するか」を調査する言語モデルを意味 しているとのこと(N-gramモデルを利用したテキスト分析). 理解に時間がかかりそうなので,詳細は省いて肝心の辞書ファイルの簡単な書き方と設定の仕方を説明します.
辞書ファイルの書き方
辞書ファイルは単なるテキストファイルです.最初の行に次のように書いてください.
</s> [] silE <s> [] silB
単語表記 [出力文字列] 音素列
</s> [] silE <s> [] silB DIRECTION [右] m i g i DIRECTION [左] h i d a r i OBJECT [工学ナビ] k o: g a k u n a b i OBJECT [ラケット] r a k e q t o OBJECT [ドラゴンボール] d o r a g o N b o: r u
単語表記,出力文字列,音素列はそれぞれタブで区切ります. 単語表記はとりあえず適当です.次に音に対応する出力文字列を[]囲みで記述します. その後に音をローマ字表記で,子音と母音をスペース区切りで記述します. 「ん・ン」は大文字で「N」,「オー」などの長音は「o:」,「ッ」などのつまる音は 「q」で記述します.
辞書ファイルは漢字コードを「EUC」,改行コードを「LF」にして保存してください. 保存時に文字コードを選択できるテキストエディタ(terapadなど)を利用して編集してください. ちなみにファイルの拡張子はなんでも良いです.また,保存場所も任意で構いません.
辞書ファイルの設定
コントロールパネル>音声認識>「Julius SAPI Engine」の「設定」で,「言語モデル」タブを開きます.
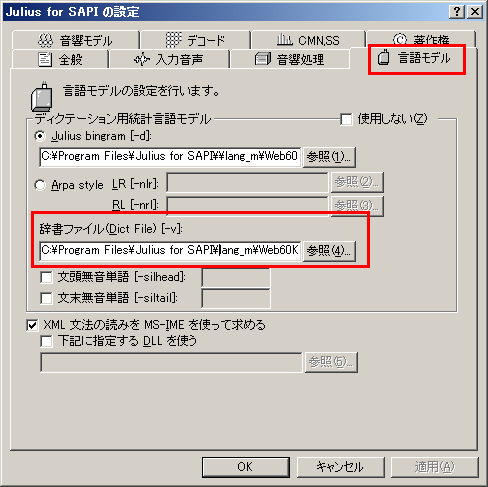
この中で辞書ファイルと書いてある項目が辞書ファイルの設定です.参照ボタンを押して自分で作った辞書ファイルを 選択しましょう.デフォルトのファイルは C:¥Program Files¥Julius for SAPI¥lang_m¥Web60K¥web.60k.htkdic になっています.
辞書に書かれている範囲でしか文字を出力しないので,なるべく似たような発音の言葉を避けて 必要な言葉だけ記述しておくと安定動作が期待できるかもしれません. 普通のおしゃべり認識を強化させたいのであれば,デフォルトの辞書をコピーして 編集するのが一番ですね.
Juliusのページ内に「クラスN-gramの使用方法」 というのがありますのでこちらも参考にされてください.
ニンテンドーDSの音声認識を利用したゲームの開発秘話に見る辞書作りのヒント
引用: “任天堂の忍者”島田健嗣氏が語る「脳トレ」の音声・手書き認識システム開発の裏側
高齢者の「きいろ(kiiro)」という発言だけ、認識率が悪いという結果が出た。分析の結果、高齢者は活舌が悪くなるため、「きいろ」という発言が、「いいろ(iiro)」、「ちいろ(tiiro)」などに誤認識されやすいのだという。 そこで島田氏らのグループは、「きいろ」の副辞書として、「いいろ」、「ちいろ」を登録した。つまり、「きいろ」という答えの際に、「いいろ」や「ちいろ」が音声入力されても、それを正解にしてしまうのである。本来誤りとなる曖昧な入力も正解としてしまうという方法は,ゲームなどの限定された状況下では威力を発揮する方法ですね.
おわりに
説明は以上です.上で紹介したプログラムソースをもとにいろいろな応用ができると思います.ぜひお試しください.
<おまけ>
さて,音声認識で何かやろうということでいろいろ考えた結果,ロボット制御が一番面白そうだったので, 友人の協力のもと巷で話題のプチロボを使ってボイスコントロールロボットを作ってみました. 「右!」「左!」の号令に従い,右手/左手を上げます.

音声認識プチロボ →動画(1.03MB)
- VoiceTestRobot01.zip(35KB)